
Duplicate parts are the software bugs of the data world—they’re hard to identify without specific tools and processes in place. If these “bugs” are not found during implementation, your PLM setup will become extremely time-consuming and costly down the road.
To put your organization in the best position for a successful PLM migration, you’ll want to give yourself enough lead time (i.e. six to 12 months) prior to the implementation to find duplicate parts and formulate a plan to deal with them.
To exterminate the duplicate data pest, follow these four critical steps.
1. Collect and Classify the Data
It is key to run any duplicate analysis off of a specific category of data—which is why your first step is to classify the parts. Start by gathering all the purchase part data together from each legacy system, including:
- Manufacturing part numbers
- Supplier names
- Pricing
- Existing internal part numbers
- Descriptions
- Any existing commodity codes
Typically, data from different systems need to be classified into a single data model, which will help dictate the categories. This, in turn, drives the attributes and allowed values of each part.
2. Enrich and Validate the Data
Once all the data from each system is classified, it’s time to enrich the data. You can harvest attribute data for each part using the manufacturer part numbers and associated source documentation.

The data is usually obtained from approved manufacturer websites or company-approved documentation (e.g specifications, drawings, etc.). The harvested data should be loaded into a database and validated against the data model.
For example, when validating air conditioner motors, enriching each motor with key information such as horsepower, speed, number of poles, phases, and frequency allows you to group duplicate motors and similar motors more easily. In some cases, motors with different manufacturer part numbers can have very similar characteristics.
3. Perform a Duplicate and Near Duplicate Analysis
Once the data has been enriched, normalized and validated, perform a duplication analysis. When grouping similar parts to help find near duplicates, a clustering tool will be helpful.
At Convergence Data, we refer to this as “neighbor distance.” It allows different weighting factors to be set on the critical attributes and the overall cluster. To make this analysis work, you must have normalized data with separate units of measurement.
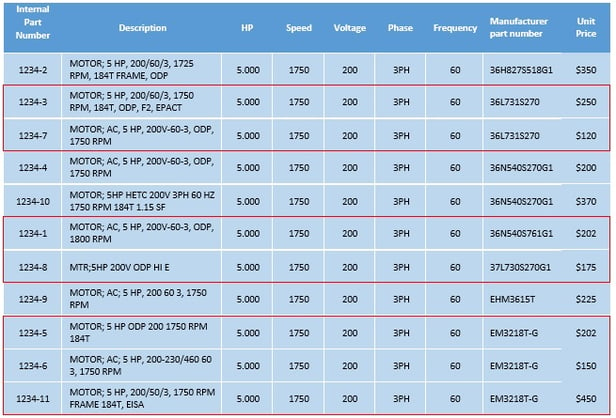
These parts have the same attribute values and therefore may be duplicates.
4. Process Identified Duplicates
Last, take the groups of duplicates and select one internal part number to be the master for each manufacturer part number (MPN). Since you will likely end up with multiple internal part numbers for an MPN, we recommend setting up a master cross reference—this will consolidate spend and rationalize your inventory without disrupting existing BOMs.
Additionally, it’s encouraged to manage the master cross reference of internal part numbers to the MPN in your ERP system. Over time, engineering can use the master internal part number for new products, which allows a slow phase-out of the other internal part numbers.
Solve Your Classification Problems
Rich attribution and classification of data are pivotal to preventing and identifying duplicate and near duplicate data that lies within your systems today. Sign up for our Classification Community today for more tips on controlling duplicates.
