
It’s no secret. We are officially living in the era of big data. Nearly every business—especially large-scale enterprises—collects, stores, and analyzes data for the benefit of growth. In most daily business operations, managing data is a norm, using tools such as:
- Databases
- Automation systems
- PLM, PIM and ERP platforms
If you have worked in any company for some time, then you’ve probably encountered the term data normalization. A best practice for handling and employing stored information, data normalization is a process that helps improve success across an entire company.
Here is some things to know about data normalization along with some tips on how to improve your data effectively. 💪
What is data normalization?
Data normalization is a process in the development of clean data. Diving deeper, however, the meaning or goal of data normalization is twofold:
- Data normalization is the organization of data to appear similar across all similar records or product families.
- It increases the cohesion of entry types leading to cleansing, enabling customer product selection, parts re-use, and higher quality data.
👉 Simply put, this process includes eliminating unstructured data and redundancy (creating duplicates) in order to ensure correct categorization. When data normalization is done correctly, you will end up with standardized information entry for all new items. For example, this process applies to how products are categorized, including standardizing descriptions and associated attribute profiles. These standardized information fields can then be grouped and read more easily, making it much simpler for a customer to find a product for purchase or for an engineering looking for a part for re-use or enabling procurement to rationalize spend for similar items.
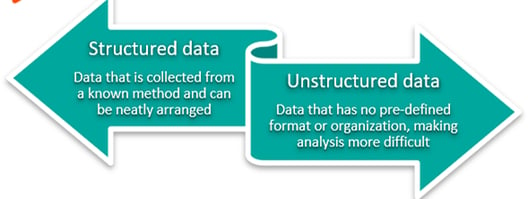
Who needs data normalization?
Every business that wishes to run successfully and grow needs to regularly perform data normalization. It is one of the most important things you can do to get rid of errors that make running information analysis complicated and difficult. Such errors often sneak up when changing, adding, or removing system information. When data input error is mitigated, an organization will be left with a well-functioning system that is full of usable, beneficial data.
With normalization, an organization can make the most of its data as well as invest in data gathering at a greater, more efficient level. Looking at data to improve how a company is run becomes a less challenging task, especially when cross-examining. For those who regularly consolidate and query data from software-as-a-service applications as well as for those who gather data from a variety of sources specifications, digital sites, and more, data normalization becomes an invaluable process that saves time, space, and money. 💰
How data normalization works
Now is the moment to note that, depending on your specific type of data, your normalization will look different.
At its most basic foundation, normalization is simply creating a standard format for all data throughout a company:
- SS or S Steel is written as Stainless Steel
- 10 1/4 milli's as 10.250 mm
- THRST BRG as Thrust Bearing
- GRNG as Grainger
Beyond basic formatting, experts agree that there are general rules or levels to performing data normalization. Each level focuses on putting entity types into categories depending on similarities. Once categorized the data needs to be standardized to ensure it can be leveraged by the organization.
The 4 Levels of Normalization
👋 Here is a simple process to follow to help standardized items down to the lowest level of data formatting including:
Level 1 - Categorizing Similar Items
Level 2 - Attribute Types and Standard Formats
Level 3 - Style Guides
Level 4 - Integration Data Rules
Let's dive into each level.
Level 1 - Categorizing Similar Items with Standard Attributes
It's critical to set up a classification structure to make it easy to normalize your data. Using a relational database with a data model is a good place to start. Set up a classification of your items consisting of categories and attributes. Then align your items against this structure.
An example category of Machine Screws might include the following attribute schema: Brand, Length, Diameter, Thread Type, Hardness, Finish, Head Shape
Level 2 - Attribute Types and Standard Formats
The attributes you assigned to each category should be defined correctly. Numeric attributes should be assigned specific units of measures and string (text) attributes ideally need a list of acceptable values. Defining the acceptable values ensures consistency of how end users or customers will view this data. Keeping units of measure consistent is critical as well - you wouldn't want a customer to have to choose between filtering a conflicting mix of imperial and metric measurements.
Example 1 (unit of measure):
Diameter = 10.250 IN
Example 2 (list of values):
Head Shape = Pan Head, Flat Head, Round Head, Oval Head, Truss Head, Hex Head
Level 3 - Style Guidelines
For attribute values, units of measure, descriptions, and other data, you may need specific rules or guidelines for formatting. Numeric attributes would require guidelines on the number of decimal places, or whether and when to use fractions. For each product description there should be a specific format or description template that dictates how the information appears, including use of abbreviations, trademarks and brand names. It helps to have guides for abbreviations, special characters, and preferred terms for all of your data, and to publish these guidelines across your business so anyone creating or modifying data adheres to a common usage of style. Importantly, data needs to be normalized before it can be abbreviated.
Level 4 - Integration Data Rules
If your data is normalized it makes it much easier to validate this data for export to systems that have specific data rules. For example, PLM systems have rules on conversions between imperial and metric. Many systems such as ERPs and PIMs have limitations on description field lengths. Wherever you stage your data, it's key to understand the rules of downstream or target systems that will consume and present that data in order to ensure that normalized data is fit for purpose.
Benefits of data normalization
🔎 As mentioned above, the most important part of data normalization is better analysis leading to growth; however, there are a few more incredible benefits of this process:
- Fewer Duplicates: When databases are crammed with information, organization and elimination of duplicates frees up much-needed space. When a system is loaded with unnecessary duplicates, cross functional efforts are duplicated. Unnecessary design time, material handling, inventory management, customer confusion, supplier management and quality control can all be addressed.
- Faster Queries: Speaking of faster processes, after normalization becomes a simple task, you can organize your data without any need to further modify. This helps various teams within a company save valuable time instead of trying to translate unstructured data that hasn’t been organized correctly.
- Business Integration: One of the best ways to grow a business is to acquire other businesses. With data normalization, it will take less time migrating new business and its data against corporate standards to help achieve economies of scale. The last thing you want to do is migrate duplicate items or unstructured data after committing to normalizing your data.
- Increased eCommerce Revenue and Customer Satisfaction: Normalization promotes findability by easing site navigation, search and browsing experiences. If customers can filter product results that require normalized attribute values and units of measure to function, they will more rapidly uncover the products they need, which keeps them using your website and makes it more likely for them to purchase your products.
The benefits of data normalization are clear. If you'd like to see how Convergence can help cleanse and normalize your data so you can achieve these outcomes, reach out today for a demo! 📝
